Claude Code wird für viele zum primären Arbeitswerkzeug, nicht nur zum Coden, sondern auch zum Analysieren, Auswerten, Reporten. Damit das in der Marketing-Praxis trägt, braucht es eine ehrliche Antwort auf die Frage: Wie kommen die Daten rein? Diese Anleitung beschreibt mein produktives Setup: fünf Datenquellen über lokale Model-Context-Protocol-Server (MCP) sauber an Claude Code angebunden, dazu fünf Cloud-Konnektoren via claude.ai, alles unter einer Konfiguration, alles synchronisiert via Repo.
Der Stack deckt das gesamte Digitalmarketing ab: GA4 für Web-Analytics, Google Ads für Paid Search, Meta Ads für Paid Social, Google Search Console für Organic Search, Screaming Frog für technisches SEO und DataForSEO für SERP- und Keyword-Intelligenz. Das ist keine Tool-Sammlung, sondern eine Infrastruktur und du kannst sie beliebig erweitern.
Wer einzelne Kanäle separat anbinden möchte, findet zu jeder Plattform eine eigene Anleitung in der Serie über das Anbinden von Marketing-Daten an Claude Code. Dieser Post hier ist das Architektur-Pendant dazu: wie alles zusammen funktioniert.
Am Ende des Artikels steht ein konkreter Workflow, der zeigt was möglich wird, sobald alle Kanäle in einem einzigen Claude-Code-Lauf zusammenkommen: ein Prompt, 50 URLs, drei Datenquellen synthetisiert zu einer priorisierten OnPage-Roadmap.
Wer mit Claude Code anfängt, hat oft einen MCP installiert, vielleicht zwei. Der Sprung zur kanalübergreifenden Arbeitsplattform passiert erst, wenn alle relevanten Datenquellen verlässlich und einheitlich da sind und Claude lernen kann, sie zu kombinieren. Genau dieser Sprung ist Thema dieses Posts.
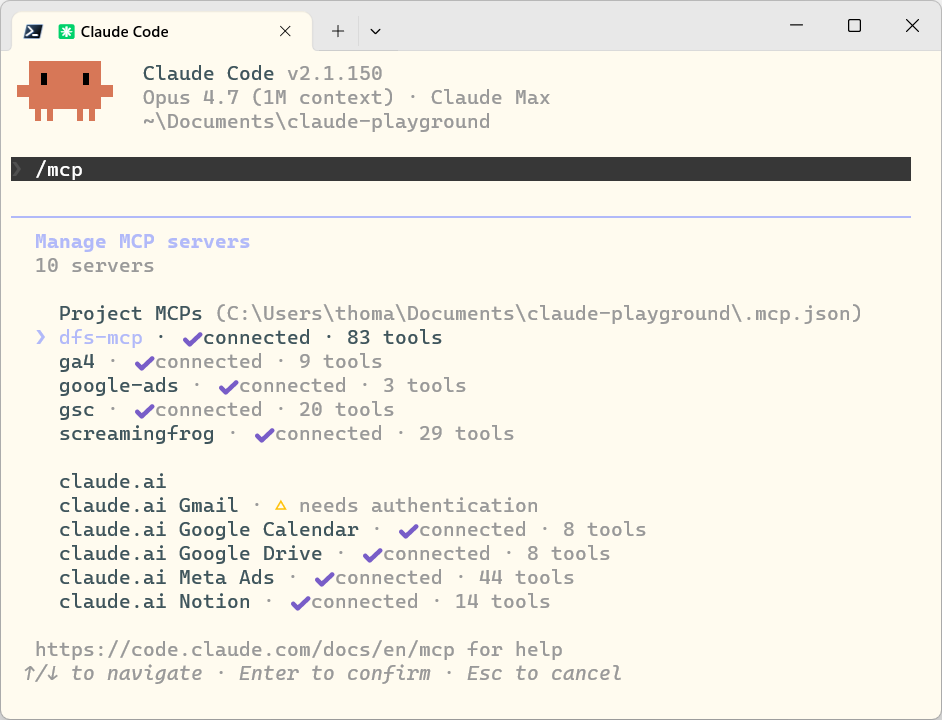
claude mcp list.Was dieser Stack abdeckt
Fünf lokale MCP-Server plus fünf Cloud-Konnektoren. Die lokalen Server werden über ein einziges .mcp.json im Workspace-Root registriert, die Cloud-Konnektoren über die claude.ai Extensions-UI verwaltet und tauchen automatisch in Claude Code auf.
| Kanal | Server | Provenance | Rolle im Workflow |
|---|---|---|---|
| Organic Search | gsc | Community (Suganthan Mohanadasan) | Klicks, Impressionen, Queries, Indexing-Status |
| Paid Search | google-ads | Offiziell (Google) | GAQL-Reads auf Kampagnen, Suchbegriffe, Auktionsdaten |
| Web-Analytics | ga4 | Offiziell (Google) | Sessions, Conversions, Funnels, Realtime |
| SEO-Intelligenz | dfs-mcp | Offiziell (DataForSEO) | SERPs, Keyword-Ideen, Backlinks, LLM-Mentions |
| Technisches SEO | screamingfrog | Offiziell (Screaming Frog Ltd.) | Crawls, Bulk-Exports, Page-Content-Extraktion |
| Cloud-Konnektoren | claude.ai | Anthropic / 3rd-Party | Meta Ads, Notion, Google Drive, Calendar, Gmail |
Drei Server laufen als lokaler Prozess (gsc, google-ads, ga4 über stdio), zwei als HTTP-Endpunkt (dfs-mcp extern, screamingfrog lokal über Port 11435). Cloud-Konnektoren leben in deinem claude.ai-Account und sind in Claude Code, Cowork und Desktop gleichermassen verfügbar.
Die spannende Beobachtung: kein einziger dieser Server allein wäre besonders. Erst die Kombination macht den Unterschied. Wenn Claude in einem Prompt GSC nach Top-URLs fragen, dieselben URLs in Screaming Frog crawlen und parallel das SERP-Umfeld via DataForSEO holen kann, entstehen Analysen, die du sonst auf vier Tabs und drei Google/Excel-Sheets verteilen würdest.
Wie das Projekt strukturiert ist
Bevor wir in die Konfiguration einsteigen: ein Blick auf den Aufbau. Der Stack besteht aus drei klar getrennten Schichten: alles, was via Repo synct, alles, was pro Gerät auf der Festplatte liegt, und die Apps, die ausserhalb davon laufen. Diese Trennung ist nicht kosmetisch, sie ist die Voraussetzung dafür, dass Credentials nicht im Repo landen und das Setup auf einem zweiten Gerät reproduzierbar bleibt.
Im Repo (synct via git)
claude-playground/ # Workspace-Root, git repo
├── .mcp.json # MCP-Server-Konfiguration (Project Scope)
├── CLAUDE.md # Geteilte Konventionen (Schweizer ss,
│ # gendergerechte Sprache, etc.)
├── kund-innen/ # Pro-Account-Ordner
│ ├── beispiel-ag/
│ │ ├── CLAUDE.md # Fence: erlaubte Account-IDs für
│ │ │ # diese*n Kund*in
│ │ └── ... # Account-spezifische Daten, Configs,
│ │ # .seospiderconfig, etc.
│ └── ...
├── mcp-setups/ # MCP-Doku und Build-Artefakte
│ ├── mcp-capabilities.md # Single Source of Truth: was kann
│ │ # welcher Server, welche Stolpersteine
│ ├── Suganthans-GSC-MCP/ # Geklontes Repo des GSC-MCPs
│ │ └── dist/index.js # Vor-gebautes Node-Artefakt, wird
│ │ # in .mcp.json referenziert
│ ├── google-ads-mcp/ # SETUP.md (pipx install)
│ ├── ga4-data-api/ # SETUP.md
│ └── dataforseo/ # SETUP.md
└── tools/ # Eigene Skripte (z.B. Marketing
# Health Report Pipeline)Die .mcp.json ist die einzige Datei, die wirklich die Server registriert. Alle SETUP.md daneben sind Lese-Doku für den Menschen, kein Konfigurations-Code.
Pro Gerät, ausserhalb des Repos
~/.api-credentials/ # Alle Credentials, gerätegebunden
├── gsc-client-secret.json # OAuth-Client für GSC
├── gsc-token.json # OAuth-Refresh-Token (auto-refresh)
├── google-ads.yaml # Dev-Token, OAuth, MCC-Login-ID
└── ga4-service-account.json # GA4 Service-Account-Key
~/.local/bin/ # pipx-installierte Binärdateien
├── analytics-mcp.exe # ga4 MCP
└── google-ads-mcp.exe # google-ads MCP
~/.claude.json # User-Scope-Config (hier nicht
# genutzt, aber existiert)Dieser Teil wird niemals ins Repo committet. Der Secrets-Ordner ist die kritische Schnittstelle und wird bei einem neuen Gerät einmal manuell kopiert.
Apps, die zusätzlich laufen müssen
- Screaming Frog Desktop (v24+, lizenziert): hostet den
screamingfrog-MCP unterhttp://localhost:11435/mcp. Muss offen sein und der MCP-Server muss in den SF-Settings gestartet werden. - claude.ai-Account (eingeloggt): hostet die Cloud-Konnektoren (Meta Ads, Notion, Drive, Calendar, Gmail). Wird nicht über die
.mcp.jsonregistriert, sondern via claude.ai → Extensions verwaltet.
Wer was referenziert
Damit das Mapping nicht abstrakt bleibt, hier die Verkettung am Beispiel des ga4-Servers:
.mcp.jsondefiniert einen Eintrag namensga4mitcommand=C:\Users\<user>\.local\bin\analytics-mcp.exe- Dieser
commandzeigt auf die pipx-installierte Binärdatei - Im selben Eintrag steht die Env-Variable
GOOGLE_APPLICATION_CREDENTIALSmit dem Pfad nach~/.api-credentials/ga4-service-account.json - Der Service-Account in dieser JSON-Datei hat (idealerweise property-level) Leserechte auf bestimmte GA4-Properties
- In
kund-innen/beispiel-ag/CLAUDE.mdist die GA4-Property dieser Kund*in im Fence aufgelistet. Claude sieht beim Start nur diese eine ID als erlaubt
Diese Kette wiederholt sich strukturell für jeden Server. .mcp.json zeigt auf eine Binärdatei oder URL, die Binärdatei wird via Env-Var auf eine Credential-Datei verwiesen, der Fence im Kund*innen-Ordner gibt Claude die erlaubten IDs.
Warum die Konsolidierung sich lohnt
Wer den Stack einmal sauber gebaut hat, bekommt dafür eine Plattform mit drei Eigenschaften, die einzeln aufgesetzte MCPs nicht bieten:
- Reproduzierbarkeit: die ganze Server-Konfiguration ist eine einzige Datei im Repo. Neuer Rechner, Kolleg*innen, frischer Klon, ein Trust-Prompt, fertig. Alle anderen Daten (Credentials, Lokal-Apps) sind klar separiert und in einer dokumentierten Liste.
- Cross-Channel-Workflows: Claude kann Datenquellen kombinieren, ohne den Kontextwechsel, den ein Mensch zwischen Tabs hätte. Das verändert, was an Analysen überhaupt machbar ist.
- Wartbarkeit: ein Provenance-Eintrag pro Server, ein Auth-File pro Server in einem Secrets-Ordner, ein zentrales Doc, das beschreibt, was wo liegt. Onboarding eines weiteren Geräts dauert Minuten, nicht Stunden.
Provenance: was ist offiziell, was Community
Wer fremden Code auf seinem System laufen lässt (und das tut man bei jedem MCP-Server), sollte wissen woher er kommt. Vor allem bei Tools, die auf Marketing-Konten zugreifen mit echten Konversions- und Spend-Daten.
| Server | Quelle | Lizenz | Bewertung |
|---|---|---|---|
gsc | github.com/Suganthan-Mohanadasan/Suganthans-GSC-MCP | Apache-2.0 | Community, aktiv gewartet, nur 4 Dependencies, schlanke OAuth-Scopes (webmasters.readonly), eigene Halluzinations-Guardrails per verify_claim-Tool. Auditierbar. Es gibt schlicht kein offizielles Google-GSC-MCP. |
google-ads | github.com/googleads/google-ads-mcp | Apache-2.0 | Aus Googles eigener googleads-Organisation. Read-only by design. |
ga4 | github.com/googleanalytics/google-analytics-mcp | Apache-2.0 | Aus Googles offizieller googleanalytics-Organisation. 2.2k Stars, aktiv gewartet. |
dfs-mcp | https://mcp.dataforseo.com/http | Proprietär | Offizieller gehosteter Endpunkt von DataForSEO. |
screamingfrog | In SF v24+ enthalten | Proprietär | Direkt von Screaming Frog Ltd. ausgeliefert, läuft in der lokalen UI. |
Die einzige Community-Komponente ist gsc. Ich nutze sie bewusst, weil das offizielle GSC-MCP fehlt und Suganthans Implementation zwei Eigenschaften hat, die selten sind: minimale Abhängigkeiten und eingebaute Faktenprüfung (verify_claim re-queryt eine numerische Behauptung gegen die API, bevor Claude sie wiederholt). Die Codebase ist klein genug um sie selbst durchzulesen.
Bei jedem Community-MCP gilt: vor der Installation einmal ins Repo schauen, Dependencies prüfen, OAuth-Scopes verstehen. Wenn googleapis und ein bekannter MCP-SDK-Build die einzigen relevanten Bibliotheken sind, ist das Risikoprofil niedrig.
Architektur-Entscheidung: Project Scope statt User Scope
Claude Code kennt drei Scopes für MCP-Server: local (eine Konfiguration pro Ordner), project (eine .mcp.json im Workspace-Root, die in allen Subordnern gilt) und user (eine globale Konfiguration in ~/.claude.json, die in jedem Projekt verfügbar ist).
Ich habe mich für Project Scope entschieden. Die .mcp.json liegt im Workspace-Root, wird mitversioniert und ist damit Teil der Single Source of Truth.
Die Argumentation:
- Ein Workspace, ein Setup: Mein Marketing-Workspace ist ein einziger Ordner mit allen Kund*innen-Unterordnern und allen Tooling-Skripten darin. Ich starte Claude Code praktisch immer von hier aus, nie von beliebigen Stellen im Dateisystem. Project Scope passt zu dieser Realität.
- Repo-Synchronisation: Wenn die
.mcp.jsonTeil des Repos ist, ist sie sofort auf einem zweiten Gerät verfügbar. User Scope würde bedeuten, dass jedes Gerät eine separate Registrierung braucht und die Konfigurationen leise auseinanderdriften können. - Trust-Prompt: Beim ersten Start im Workspace zeigt Claude Code einen Project-Scope-Trust-Prompt mit der Liste aller Server. Diesen einmal akzeptieren, fertig. Bei User Scope passiert das pro Server beim ersten Aufruf.
- Audit: Jede Änderung an den Servern erscheint als sichtbarer Git-Diff. Das ist unschätzbar wertvoll, sowohl für Reviews als auch für die eigene Erinnerung, wann was eingebaut wurde.
Wann User Scope trotzdem die richtige Wahl wäre: wenn du Claude Code wirklich von beliebigen Orten startest, mehrere unverbundene Workspaces hast, oder bewusst eine globale Default-Konfiguration willst. Für ein einzelnes konsolidiertes Workspace ist Project Scope der saubere Weg.
Das eigentliche Setup
Vorneweg: Theoretisch kannst du diese Anleitung auch einfach Claude Code geben, und Claude Code wird dich durch alle Schritte führen und allfällige Fragen beantworten.
Drei Bestandteile: die .mcp.json im Workspace-Root, die Credentials in einem zentralen Secrets-Ordner, die zwei pipx-basierten Server als lokale Installation. Plus optional die Konfiguration der Cloud-Konnektoren über claude.ai.
Voraussetzungen
node --version # >= v18
python --version # >= 3.10
python -m pipx --versionScreaming Frog v24+ separat installieren und lizenzieren. Der MCP-Server lebt in der App selbst.
Schritt 1: pipx-Server installieren
ga4 und google-ads werden über Python-Packages bereitgestellt. Wir installieren sie via pipx, damit sie isoliert in eigenen venvs liegen:
python -m pipx install analytics-mcp
python -m pipx install git+https://github.com/googleads/google-ads-mcp.gitVerifizieren, dass die Binärdateien da sind:
ls $env:USERPROFILE\.local\bin\analytics-mcp.exe
ls $env:USERPROFILE\.local\bin\google-ads-mcp.exeSchritt 2: Suganthans GSC-MCP bauen
cd mcp-setups\Suganthans-GSC-MCP
npm install
npm run buildDas Repo enthält bereits ein pre-builtes dist/index.js, der Build ist nur nötig wenn es fehlt.
Schritt 3: .mcp.json schreiben
Diese Datei kommt in den Workspace-Root. Ein anonymisiertes Beispiel mit allen fünf Servern:
{
"mcpServers": {
"gsc": {
"command": "node",
"args": ["C:\\Users\\<user>\\Documents\\workspace\\mcp-setups\\Suganthans-GSC-MCP\\dist\\index.js"],
"env": {
"GSC_AUTH_MODE": "oauth",
"GSC_OAUTH_SECRETS_FILE": "C:\\Users\\<user>\\.api-credentials\\gsc-client-secret.json",
"GSC_SITE_URL": "sc-domain:beispiel.ch"
}
},
"google-ads": {
"command": "C:\\Users\\<user>\\.local\\bin\\google-ads-mcp.exe",
"env": {
"GOOGLE_ADS_DEVELOPER_TOKEN": "<token>",
"GOOGLE_ADS_LOGIN_CUSTOMER_ID": "XXXXXXXXXX",
"GOOGLE_ADS_CONFIGURATION_FILE_PATH": "C:\\Users\\<user>\\.api-credentials\\google-ads.yaml",
"GOOGLE_PROJECT_ID": "<gcp-project-id>"
}
},
"ga4": {
"command": "C:\\Users\\<user>\\.local\\bin\\analytics-mcp.exe",
"env": {
"GOOGLE_APPLICATION_CREDENTIALS": "C:\\Users\\<user>\\.api-credentials\\ga4-service-account.json",
"GOOGLE_PROJECT_ID": "<gcp-project-id>"
}
},
"dfs-mcp": {
"type": "http",
"url": "https://mcp.dataforseo.com/http",
"headers": {
"Authorization": "Basic <base64-of-username:password>"
}
},
"screamingfrog": {
"type": "http",
"url": "http://localhost:11435/mcp"
}
}
}Wichtig: alle Pfade sind absolute Windows-Pfade mit doppelten Backslashes. ~ und Umgebungsvariablen wie $env:USERPROFILE werden in .mcp.json nicht expandiert.
Hinweis zu GSC_SITE_URL: das Beispiel oben setzt eine einzige Property als Default. Wenn du mit mehreren GSC-Properties arbeitest, lass die Zeile weg und nenne die Property pro Lauf im Prompt oder im Account-Fence (siehe Multi-Account-Sektion weiter unten). Sonst kapselt dein Workspace-Setup die Property auf eine einzige fest.
Schritt 4: Credentials zentral ablegen
Ein Ordner ~/.api-credentials/ (Naming nach Geschmack) hält alle Auth-Files:
gsc-client-secret.json: OAuth-Client für die GSC-Anbindunggsc-token.json: wird beim ersten Browser-Sign-In automatisch erzeugtgoogle-ads.yaml: Developer Token, OAuth Refresh Token, MCC-IDga4-service-account.json: JSON-Key des GA4 Service Accounts
Den base64-String für die DataForSEO-Authentifizierung trage ich direkt im headers-Block der .mcp.json ein. Wer ihn lieber aus einer Umgebungsvariable lesen will, kann zusätzlich eine .env in diesem Ordner halten und sie aus seiner Shell laden, bevor er Claude Code startet.
Dieser Ordner wird niemals ins Repo committet. Er ist gerätegebunden und muss bei einem neuen Rechner manuell kopiert werden.
Schritt 5: Trust-Prompt akzeptieren und verifizieren
Beim ersten Start im Workspace:
cd C:\path\to\workspace
claudeClaude Code zeigt den Project-Scope-Trust-Prompt mit der Liste aller fünf Server. Akzeptieren. Danach in der Session:
/mcpoder im Terminal:
claude mcp listErwartete Ausgabe: vier ✓ (gsc, google-ads, ga4, dfs-mcp) und ein ✗ für screamingfrog, bis du die SF-Desktop-App startest und dort den MCP-Server einschaltest.
Die Stolpersteine, die du wirklich triffst
Beim Aufbau habe ich genau diese Stolpersteine getroffen. Sie kosten alle Zeit, weil keiner davon eine sprechende Fehlermeldung produziert.
pipx-PATH greift nicht in laufenden Shells
Nach python -m pipx ensurepath wird der PATH der neuen PowerShell-Sessions aktualisiert, nicht der aktuellen. Eine bestehende Claude-Code-Session sieht die Änderung nicht. Lösung: neues Terminal öffnen, Claude Code neu starten.
Der eigentliche Trick ist, in .mcp.json die .exe-Dateien direkt mit absolutem Pfad anzusprechen (C:\Users\<user>\.local\bin\google-ads-mcp.exe) statt pipx run. Dann ist die PATH-Frage zur Laufzeit irrelevant.
GOOGLE_PROJECT_ID ist required, der Fehler ist silent
Der Google-Ads-MCP nutzt zwar die google-ads.yaml für die Auth, braucht aber zusätzlich GOOGLE_PROJECT_ID als Env-Variable in der .mcp.json. Ohne diese Variable startet der Server, antwortet aber auf alle Anfragen mit Auth-Fehlern, die aussehen, als wären die Credentials falsch. Sind sie nicht. Es fehlt nur die Project-ID.
GOOGLE_ADS_CONFIGURATION_FILE_PATH, nicht GOOGLE_ADS_YAML_PATH
In vielen Setup-Anleitungen taucht die Env-Variable GOOGLE_ADS_YAML_PATH auf. Der MCP-Server liest sie nicht. Die richtige Variable heisst GOOGLE_ADS_CONFIGURATION_FILE_PATH. Wenn du sie falsch schreibst, sucht der Python-Client die yaml im Standardpfad ~/google-ads.yaml und scheitert dort still.
Screaming Frog: Pre-Session-Ritual nicht vergessen
Der SF-MCP-Server läuft innerhalb der Screaming-Frog-Desktop-App. Das heisst: SF muss vor dem Claude-Code-Start offen sein, und der MCP-Server muss in SF aktiv eingeschaltet sein über File > Settings > MCP Server > Start MCP Server. Vergisst du den Schritt, antwortet http://localhost:11435/mcp mit einem Connection-Refused und claude mcp list zeigt das rote ✗.
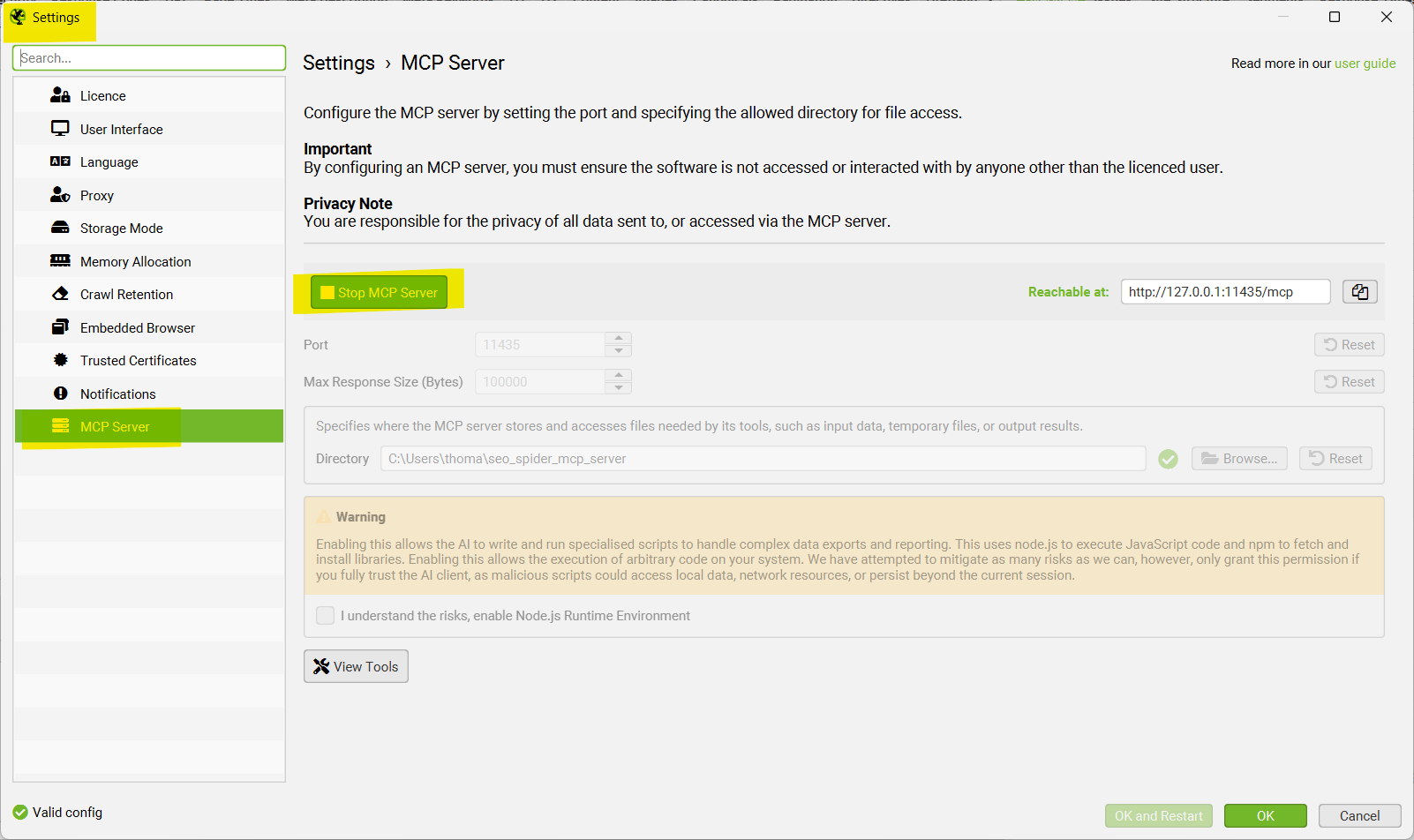
File > Settings > MCP Server > Start MCP Server.Die Node.js-Runtime-Option in den SF-Settings bleibt bewusst aus. Sie aktiviert die sf_run_node_js_script- und sf_npm_install-Tools, die wir bewusst nicht standardmässig freigeben. Wenn du sie konkret brauchst, dann gezielt einschalten, sonst aus.
DataForSEO: der /http-Endpunkt, nicht /mcp
DataForSEO hat zwei MCP-Endpunkte: https://mcp.dataforseo.com/http und https://mcp.dataforseo.com/mcp. Der neuere streamable-HTTP-Endpunkt (/mcp) wird laut DataForSEOs eigener Doku aktuell nicht von Claude unterstützt. Bleib auf /http.
Stray-.mcp.json-Dateien merging nach oben
Project-scoped .mcp.json-Dateien werden vom Workspace-Root nach unten gefunden und aufwärts gemerged. Wenn du irgendwo in einem Unterordner einer fremden Library (z.B. einem geklonten Beispiel-Repo) eine .mcp.json hast, wird sie mit deiner Hauptkonfiguration vermischt und kann unbeabsichtigte Server hinzufügen oder Variablen überschreiben.
Mein Fix: alle Beispiel-.mcp.json-Dateien in mitversionierten Drittprojekten in .mcp.json.example umbenennen, damit sie nicht mehr automatisch geladen werden.
Defense-in-Depth: GA4 Service Account property-level grants
Eine architekturelle Eigenheit des GA4-MCPs verdient eine eigene Sektion. Der Server authentifiziert sich über einen Google-Cloud-Service-Account. Standardmässig sieht dieser Service Account alle GA4-Properties, auf die er Leserechte hat. Wenn der Service Account Account-weite Leserechte hat, sieht er alle Properties, und Claude kann sie alle anfragen.
Best Practice: dem Service Account property-level Leserechte geben statt account-weit. Das heisst: in der GA4-Admin-Oberfläche pro Property gezielt den Service-Account-Email-Account als Viewer hinzufügen, statt ihm auf Account-Ebene Rechte zu erteilen. Damit kann Claude API-seitig schlicht nicht auf Properties zugreifen, die du nicht explizit freigegeben hast.
Das ist die einzige Stelle im Stack, an der ich Daten-Isolation auf API-Ebene erzwingen kann. Bei allen anderen Servern (Google Ads, Meta, GSC) ist die Isolation eine Frage von Konfiguration und Disziplin im Prompt. Defense-in-Depth gilt hier nur auf einer Schicht. Das ist ehrlich und sollte so kommuniziert werden, statt eine Sicherheit zu suggerieren, die der Stack nicht hat.
Optional: Multi-Account-Pattern für Agenturen und Inhouse-Teams mit mehreren Properties
Wer den Stack nur für einen einzelnen Account nutzt, kann diese Sektion überspringen. Wer mit mehreren Google-Ads-Konten, mehreren GA4-Properties oder mehreren Meta-Ad-Accounts arbeitet, sollte sie lesen.
Das Problem: Ein einziges Google-OAuth sieht alle Google-Ads-Customer-IDs, denen der zugehörige Account Zugriff hat. Ein einziges Meta-Login sieht alle Ad Accounts unter dem Business Manager. Wenn du Claude in einem Prompt für Account A arbeiten lässt, kann er ohne weiteres Daten von Account B mit hereinziehen, entweder absichtlich (auf Nachfrage der User*in) oder versehentlich (wenn die Anfrage nicht eindeutig formuliert ist).
Die Lösung in meinem Setup: pro Account ein eigener Unterordner mit einer eigenen CLAUDE.md, die die erlaubten IDs explizit auflistet und Claude anweist, sich nur in diesem Set zu bewegen.
Beispiel-Fence in kund-innen/beispiel-ag/CLAUDE.md:
# Beispiel AG: Account-IDs (LOCKED)
Diese Liste enthält die einzigen Account-IDs, die du in diesem
Projekt anfragen darfst.
- GA4 property: properties/XXXXXXXXX
- Google Ads customer: XXX-XXX-XXXX
- GSC property: https://www.beispiel.ch/
- Meta ad account: act_XXXXXXXXX
- DataForSEO target: beispiel.ch
- Screaming Frog cfg: beispiel.seospiderconfig
## Hard rule
Nutze ausschliesslich die oben genannten IDs. Liste keine
anderen Accounts auf und wechsle nicht zu anderen Properties,
auch wenn die Logins technisch mehr sehen würden. Falls eine
Aufgabe eine ID erfordert, die nicht hier steht, stoppe und
frage nach, bevor du einen Tool-Call machst.Claude Code lädt CLAUDE.md aus dem aktuellen Ordner und allen Eltern-Ordnern beim Start. Wenn du also Claude aus kund-innen/beispiel-ag/ startest, wird genau dieser Fence aktiv, nicht der Fence eines anderen Accounts.
Wichtig zu verstehen: dieser Fence ist advisory, nicht enforced. Er ist eine Anweisung an das Modell, kein Sandbox. Wenn du Claude explizit befiehlst eine andere ID anzufragen, wird er es tun. Was der Fence schützt, sind versehentliche Cross-Account-Anfragen, nicht böswillige. Für API-seitige Enforcement siehe die GA4-Sektion oben. Das ist der einzige Server in diesem Stack, der das überhaupt erlaubt.
Die einzige Disziplin, die du dir antrainieren musst: Claude Code immer aus dem Account-Ordner starten, nie aus dem Workspace-Root. Das ist die Disziplin, die den Fence aktiviert.
Cross-Device-Realität
Was synct über das Repo, was nicht:
| Synct über Repo | Synct nicht (pro Gerät separat) |
|---|---|
.mcp.json | ~/.api-credentials/-Inhalt |
CLAUDE.md-Fences | pipx-Pakete (analytics-mcp, google-ads-mcp) |
Suganthans-GSC-MCP/dist/ | Screaming Frog Installation + Lizenz |
| Skripte und Konfigurationen | claude.ai-Login (Cloud-Konnektoren) |
Pro neuem Gerät heisst das: Repo klonen, Node und Python installieren, die zwei pipx-Pakete installieren, Secrets-Ordner manuell kopieren, SF installieren, claude.ai-Login durchführen. Dauert eine knappe Stunde wenn man weiss was man tut, mehr beim ersten Mal.
Ein subtiler Punkt: Pfade in der .mcp.json sind userprofile-spezifisch. Auf meinem Hauptrechner sind sie C:\Users\thoma\..., auf einem zweiten Gerät mit anderem Windows-Benutzernamen (etwa Thomas) müsste ich die Pfade einmalig per Find-Replace anpassen. Das ist der einzige nicht-portable Teil des Setups. Wer den Workspace cross-platform nutzen will (Mac und Windows), wird hier mehr Aufwand haben, weil Pfade sich strukturell unterscheiden, nicht nur im Benutzernamen.
Der vollständige Workflow: 50 URLs in einem Prompt
Jetzt das versprochene Beispiel. Der folgende Prompt nutzt drei der fünf lokalen MCP-Server (gsc, dfs-mcp, screamingfrog) und produziert in einem Durchlauf eine priorisierte OnPage-Optimierungs-Roadmap für die Top 50 URLs einer Property. Was ein Mensch über Stunden in Excel-Sheets bauen würde, läuft hier in einem strukturierten Lauf mit klaren Zwischenstopps.
Bevor du den Prompt nutzt, starte Claude Code aus dem entsprechenden Account-Ordner (damit der Fence greift), trage die echten Property-URLs im Fence ein, und stelle sicher, dass Screaming Frog läuft mit gestartetem MCP-Server.
Der Prompt:
Du bist mein*e SEO-Analyst*in für [KUND*IN]. Ich arbeite aus dem Ordner
kund-innen/[kund-in]/, der Fence in CLAUDE.md lockt die erlaubten
Property-IDs für GSC, GA4 und Google Ads sowie den DataForSEO-Scope
auf den Schweizer Markt.
Kontext
- Markt: Schweiz, Sprache de-CH
- Zeitraum für GSC-Daten: letzte 90 Tage
- SERP-Location: 2756 (Schweiz), language_code "de"
- Ziel: priorisierte OnPage-Optimierungs-Roadmap für die wichtigsten 50 URLs
Aufgabe: bitte in dieser Reihenfolge ausführen und nach Schritt 2
stoppen für mein "go", bevor DataForSEO-Credits verbrannt werden.
Schritt 1: Top-Performer identifizieren (GSC)
Hole für die Property [PROPERTY-URL] die Top 50 URLs sortiert nach
organischen Klicks aus der Schweiz (country = che), Zeitraum
letzte 90 Tage. Ergebnistabelle: URL | Klicks | Impressionen | CTR
| Ø-Position.
Schritt 2: Suchintention pro URL (GSC)
Für jede der 50 URLs aus Schritt 1: hole die 3 meistgeklickten
Queries aus der Schweiz, selber Zeitraum. Konsolidiere in einer
Tabelle: URL | Top-Query 1 (Klicks, CTR, Position) | Top-Query 2
(...) | Top-Query 3 (...).
→ Zeig mir Schritt 1+2 als kombinierte Tabelle und warte auf
mein "go" bevor du Schritt 3 startest.
Schritt 3: Wettbewerbslandschaft (DataForSEO)
Für die jeweils top-geklickte Query pro URL (also 50 Queries):
hole das organische SERP-Top-5 via serp_organic_live_advanced.
Location 2756, language "de". Extrahiere pro Position 1–5:
ranking URL, Title Tag, Meta Description. Batch wo möglich.
Wenn eine Query kein SERP zurückgibt: explizit als "kein SERP"
markieren, nicht erfinden.
Schritt 4: Eigene OnPage-Realität (Screaming Frog)
Crawle die 50 URLs aus Schritt 1 im List-Mode. JavaScript-
Rendering einschalten falls die Site SPA-Anteile hat. Extrahiere
pro URL: Title Tag (+ Länge in Zeichen und Pixel), Meta
Description (+ Länge), H1, H2-Liste, Word Count, Hauptcontent
(via bulk export page content für die Synthese in Schritt 5).
Falls einzelne URLs nicht crawlbar sind (4xx/5xx/Robots): in der
Ergebnistabelle markieren, nicht überspringen.
Schritt 5: Synthese und Optimierungsempfehlungen
Pro URL eine strukturierte Empfehlung mit folgenden Feldern:
- URL
- Status quo: aktueller Title Tag, Meta Description, H1
- Top-Query und abgeleitete Suchintention
(informational / commercial / transactional / navigational)
- Was die SERP-Konkurrenz macht: Muster in Title-Länge, Position
des Keywords im Title, wiederkehrende Modifier (z.B. "2026",
"Schweiz", "Vergleich", USPs wie Preis/Garantie)
- Empfehlung Title Tag: konkreter Vorschlag, max 60 Zeichen,
Pixel-grob ≤580px, Brand am Ende
- Empfehlung Meta Description: konkreter Vorschlag, 140–160
Zeichen, mit CTA-Element
- Empfehlung H1 und H-Struktur: nur wenn aktueller H1 nicht zur
Top-Query passt
- Content-Gap: welche Subtopics oder Entities in der Top-5
ranken die in meinem Content fehlen, abgeleitet aus den
Konkurrenz-Titles und ggf. den von SF extrahierten H-Strukturen.
Nicht halluzinieren, nur was in den Daten belegbar ist.
- Priorisierung: Quick Win / Medium / Strategisch
Output-Format
- Schritte 1, 2, 3 und 4 jeweils als Markdown-Tabelle
- Schritt 5 als strukturierte Liste pro URL, gruppiert nach
Priorisierungs-Bucket
- Ganz am Ende: Top-10-Massnahmen über alle 50 URLs sortiert nach
geschätztem Klick-Impact (Klick-Volumen × CTR-Lücke zu Position 1)
Constraints
- Keine Halluzinationen: fehlende Daten als "keine Daten" markieren
- Sprache: alle Empfehlungen in Schweizer Standarddeutsch (ss statt ß),
du-Form, Kund\*innen-Schreibweise mit Asterisk
- Bevor Schritt 3 startet: Schritt 1+2 zeigen und auf "go" warten
- Falls das DataForSEO-Budget pro Call ein Limit hat, das ich kennen
sollte: vor dem ersten Call grob abschätzen und mir mitteilenWelcher MCP macht was
| Schritt | MCP / Tool | Konkreter Call |
|---|---|---|
| 1 | gsc | advanced_search_analytics mit dimensions=page, country-Filter |
| 2 | gsc | advanced_search_analytics mit dimensions=page,query |
| 3 | dfs-mcp | serp_organic_live_advanced (batched über 50 Queries) |
| 4 | screamingfrog | sf_crawl (List-Mode) + sf_bulk_export_page_content |
| 5 | (keiner) | Claude synthetisiert aus den Outputs der Schritte 1–4 |
Der Punkt ist nicht, dass ein einzelner Server etwas Spezielles tut. Der Punkt ist, dass die Kombination einen Workflow ermöglicht, der ohne diesen Stack über mehrere Tools, mehrere Exports und mehrere Stunden manueller Arbeit gehen würde.
Analoge Cross-Channel-Workflows, die mit demselben Stack möglich sind, ohne sie hier voll auszuformulieren:
- “Vergleiche die Performance meiner Google-Ads-Keywords mit den organischen Rankings in GSC für die gleichen Suchbegriffe. Markiere wo ich für Klicks bezahle, die ich organisch ebenfalls bekomme.” (Google Ads + GSC)
- “Welche Landing Pages aus meinen Meta-Ads-Kampagnen haben die höchsten Bounce Rates in GA4? Crawle diese URLs in Screaming Frog und identifiziere strukturelle Schwächen.” (Meta Ads via Cloud-Konnektor + GA4 + SF)
- “Erstelle eine Wochenübersicht: Spend, Conversions und ROAS je Kanal (Google Ads, Meta Ads), Organic Sessions aus GA4, Top-Bewegungen in GSC.” (Google Ads + Meta Ads + GA4 + GSC)
Wann dieser Stack nicht passt
Drei Konstellationen, in denen ich von dem Setup abraten würde:
- Reines Team-Setup ohne persönlichen Workspace: wenn mehrere Personen den gleichen Workspace teilen sollen, brauchst du ein anderes Modell. Credentials müssen zentralisiert werden, Trust-Prompts pro Person geklärt, Audit-Trails mitgedacht. Das geht, ist aber ein anderer Post.
- Cross-Platform-Setup mit Mac und Windows gemischt: Pfade in der
.mcp.jsonsind strukturell unterschiedlich. Du kommst nicht mit Find-Replace aus, du brauchst zwei separate.mcp.json-Dateien oder eine Build-Logik, die sie aus einer Template generiert. - Wenn du nur einen einzigen MCP brauchst: für nur GA4 oder nur GSC ist der hier beschriebene Aufwand Overkill. Dann installierst du den einen Server, ohne diese Architektur.
Für alle anderen Konstellationen (Solo, Inhouse-Team mit klar zugewiesenen Accounts, kleine Agentur, dedizierter Marketing-Workspace) ist die Investition in den vollständigen Stack die Zeit wert. Spätestens beim zweiten Cross-Channel-Workflow, der ohne diesen Stack nicht möglich gewesen wäre, hat sich die Setup-Zeit amortisiert.
Weiterführende Anleitungen pro Kanal
Wer einen einzelnen Kanal separat anbinden will, findet jede Plattform in der Serie: